
裁剪:裁剪部 JHZ开云kaiyun
【新智元导读】GPT-4.5上线一天,一经引起了集体群嘲:这个模子彻里彻外失败了,OpenAI一经堕入严重窘境,失去护城河!有东谈主算出,GPT-4.5比DeepSeek V3贵了500倍,性能却更差。有的泰斗AI展望者看完GPT-4.5,气得平直把AGI展望时刻推后了……天然了,OpenAI并不这样合计。
自从OpenAI发布GPT-4.5之后,Ilya这张图又开动火了。
GPT-4.5令东谈主失望的发扬,再次印证了Ilya这句话的含金量:预西宾一经达到极限,推理Scaling才是将来有但愿的范式。
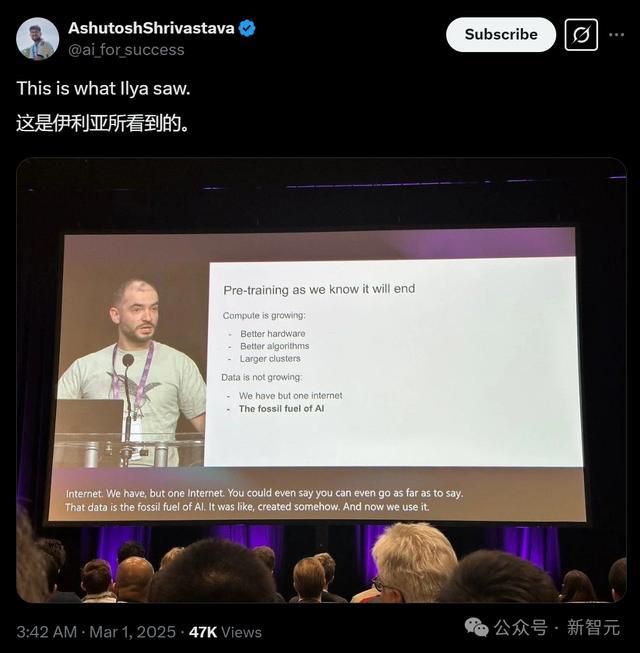
GPT-4.5在基准测试上并莫得擢升,推理莫得增强,仅仅酿成了一个更易于合营、更有创造性、幻觉更少的模子。
GPT-4.5的「失败」愈加讲明,Ilya是对的。
当今,各方评测齐一经出炉,约束深远,OpenAI确凿是太打脸了。
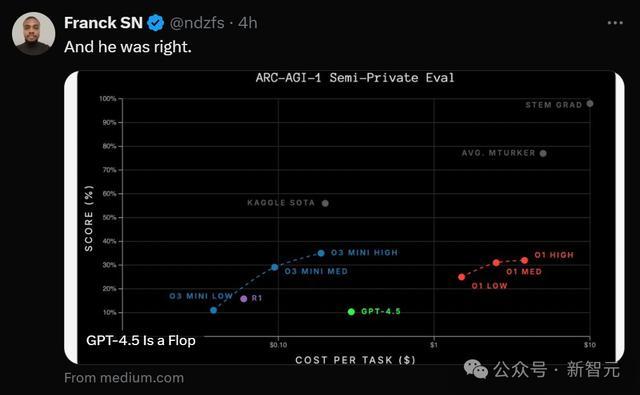
从ARC-AGC的评估上来看,GPT-4.5简直跟GPT-4o处于吞并水平,智能上似乎莫得任何擢升。
纽约大学教学马库斯平直发长文痛批:GPT-4.5即是个空腹汉堡。

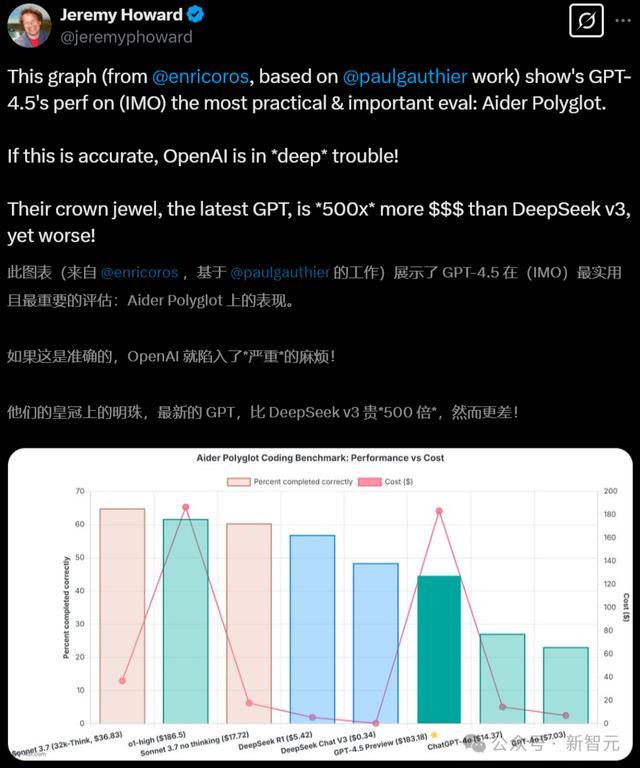
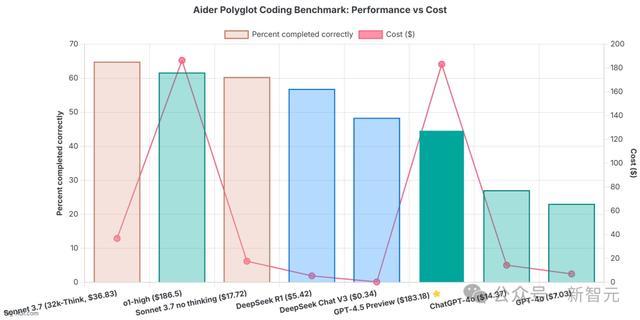
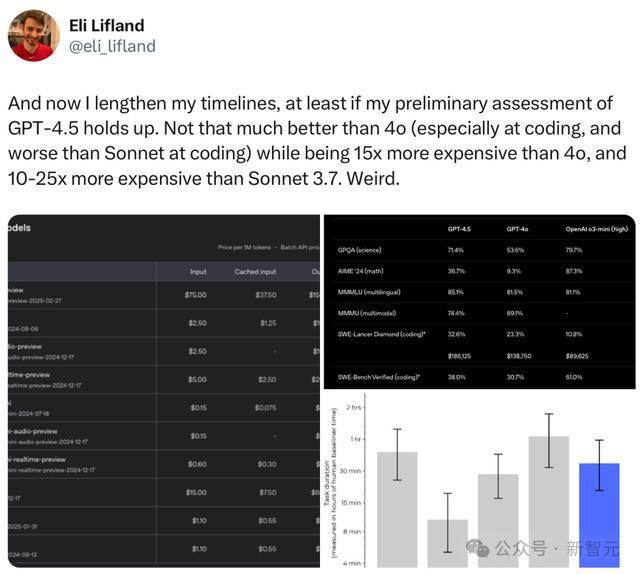
一位AI初创CEO更是直言:在我方心目中最实用评估基准Aider Polyglot上,OpenAI的「镇国之宝」GPT-4.5,比DeepSeek-V3贵了500倍,但发扬反而更差。
如若这个约束准确,那OpenAI将堕入严重窘境,致使是透彻失去护城河!
与此同期,国内这边DeepSeek蚁合6天给东谈主们带来了开源暴击,R1模子平直减价75%。
总之,在DeepSeek、xAI Grok 3、Anthropic首个搀杂模子Cluade 3.7 Sonnet等的前后夹攻之下,OpenAI这位昔时明星,如今赫然已应许不再。
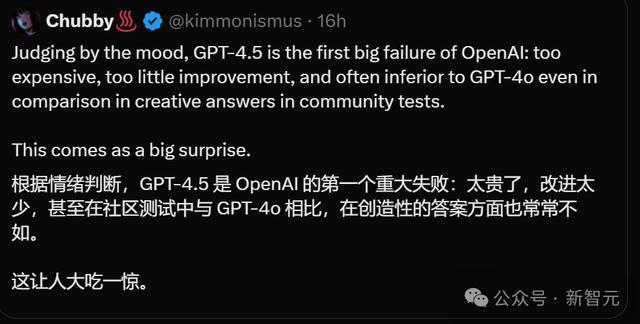
「GPT-4.5真这样差?我不会看错了吧」
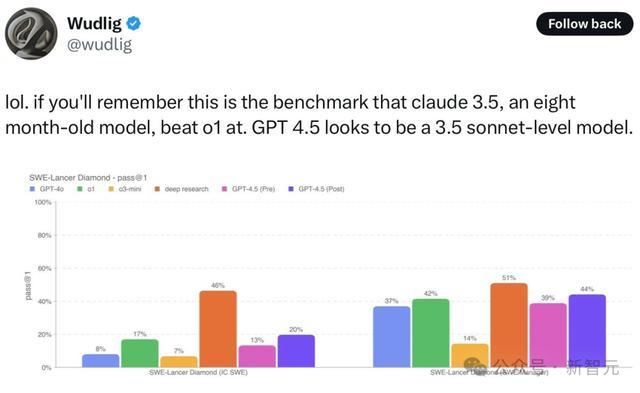
正如上文所提,刚刚那位AI初创CEO在看到底下这张图表后,嗅觉确凿难以置信,因为GPT-4.5 Preview的发扬,平直全班垫底。
为此,他还求证了表格制作家,对方示意我方仔细查验了性能数据,进行了屡次运行,能保证每个约束齐是对的。
GPT-4.5比GPT-4基础模子多出了10倍的预西宾计较量,但却什么齐不擅长,这合理吗?
有东谈主臆想说,GPT-4.5可能并莫得经过太多的监督微调,因为OpenAI原本是蓄意将其行为将来模子(如GPT-5)的基础模子或教师模子,用于进一步通过强化学习进行微调的。
可能是这个原因,导致它在代码的领导遵守上不算特别强。

或者,问题可能出在了数据搀杂上,因为OpenAI此次选择了一种全新的西宾机制,是以可能有某种「成长痛」。
不外令东谈主心凉的是:OpenAI里面许多能作念到这件事的东谈主,如今一经走了。
有东谈主平直开麦示意:「如若DeepSeek能有OpenAI的资金量,那咱们就完蛋了」。
还有东谈主戏弄谈,这可能即是所谓的「用才能换情商」吧。
不管怎样说,在大家眼中,OpenAI的先发上风一经不复存在了。
傍边滑动查抄
马库斯:OpenAI透彻失去护城河
马库斯转发了这个约束惊东谈主的筹谋后示意,不管OpenAI在两年前有什么上风,如今他们一经透彻失去了护城河。
天然他们当今仍领有响亮的名字、多数数据和广阔用户,但相对竞争敌手并未领有任何决定性的上风。
Scaling并莫得让他们走到AGI的至极。GPT-4.5杰出好意思丽,GPT-5也失败了。
悉数东谈主齐开动疑问:OpenAI能拿出的,就惟有这样多了?
当今,DeepSeek一经激发了一场价钱战,削减了大模子的潜在利润。而且,咫尺还莫得任何杀手级操纵出现。
在每一次模子的反应中,OpenAI齐在失掉。公司的烧钱速率如斯之快,但资金链却有限,连微软也不再实足相沿他们了。

如若不行快速转型为非谋利组织,一大笔投资就会酿成债务。
而且,Ilya、Murati、Schulman……许多顶尖东谈主物一经离开。
如若孙正义转变想法,OpenAI就会坐窝濒临严重的现款问题(马斯克有一句话说对了,星际之门的很大一部分资金,他们并莫得拿胜仗)。
总之,在推出ChatGPT上,奥特曼如实是阿谁正确的CEO,但他并莫得填塞的技能远见,携带OpenAI迈向下一个阶段。
在这篇《GPT-4.5是个空腹汉堡》中,马库斯也再次强调:Scaling一经撞墙了。
在GPT-4.5发布前,他就展望将是一场空隙适,而LLM的贞洁Scaling(不管是加多数据量照旧计较)一经撞墙。
在某些方面,GPT-4.5还不如Claude上一个版块的模子。
致使第一次出现了这种情况:颇受尊敬的AI展望师感到杰出失望,以至于推迟了我方关于AGI何时到来的展望时刻。
而奥特曼在产物发布上的荒谬沉稳,就更耐东谈主寻味了。
他莫得像盛大那样大力宣传AGI,而是承认了大限制模子的资本,却对AGI实足避而不提。
总之,马库斯示意,我方在2024年的展望依然苍劲——
破钞五千亿好意思元后,依然没东谈主找到可行的生意模式,除了英伟达和一些贪图公司除外,没东谈主获取了可不雅的利益。
莫得GPT-5,莫得护城河。
「Scaling是一个假定,咱们插足了相称于阿波罗筹划两倍的资金,但于今并未取得太多本质性效果。」
GPT-4.5:不求最好,但求最贵
总之,从输入价钱来看,GPT-4.5可谓是贵到离谱:
o1的5倍
GPT-4o的30倍
o3-mini的68倍
DeepSeek-R1的137倍
DeepSeek-V3的278倍
但正如前文所说,行为「最贵」模子的GPT-4.5,在发扬上却不是「最好」的。
跑分一个第1齐莫得
由知名华侨亿万财主Alexandr Wang创办的Scale AI,按时会更新一套基于专额外据集的LLM名次榜SEAL,咫尺首页上共有15个。
关连词,在这波最新的排名中,GPT-4.5 Preview居然莫得一项取得第一!
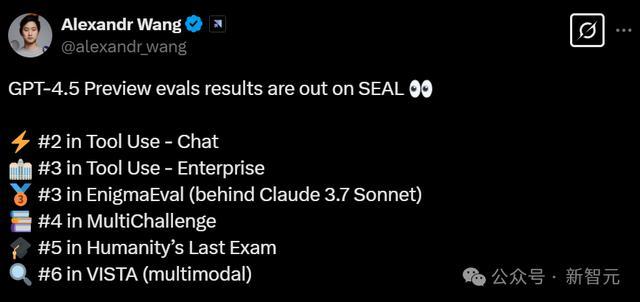
全场最好收成,是智能器具使用(Chat)神态标亚军——略强于Claude 3.7 Sonnet,但次于上一代GPT-4o。
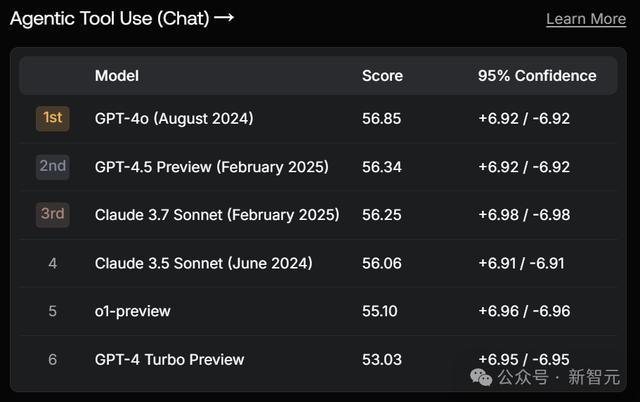
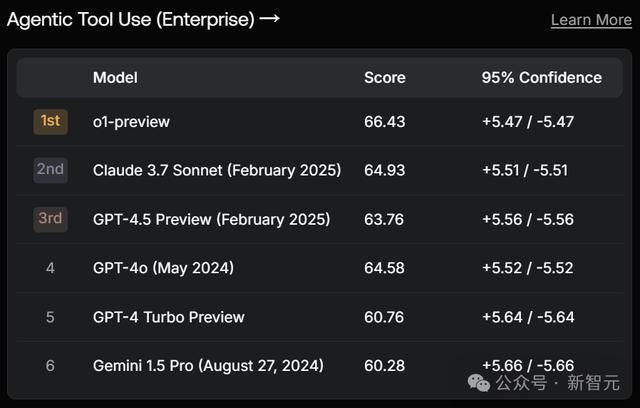
接下来,GPT-4.5在EnginmaEval,Agentic Tool Use(Enterprise)两个神态上,取得第3。
其中,前者需要创造性地惩处问题和轮廓不同范围信息的才智;后者评估模子器具使用的纯熟进程,脾气是需要将多个器具组合在一谈。
别离输给了自家的o1/o1-preview和竞争敌手最新的Claude 3.7 Sonnet(Thingking)。
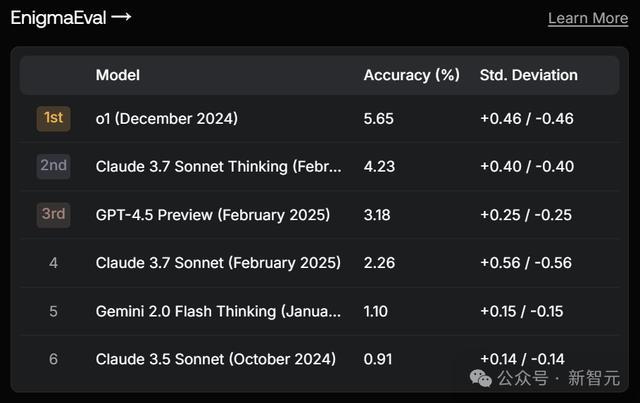
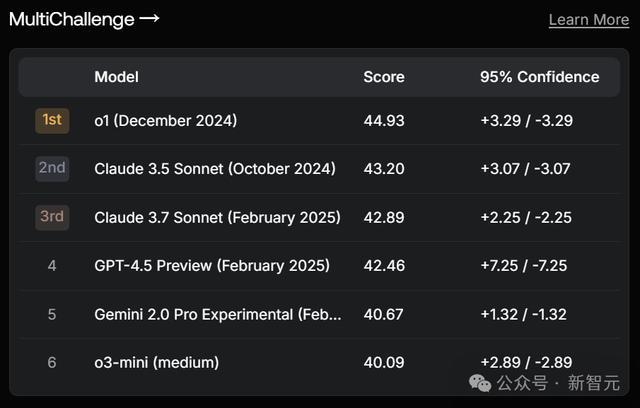
在MultiChallenge中,排名第4,输给了o1、Claude 3.5 Sonnet和3.7 Sonnet。
榜单MultiChallenge用于评估LLM与东谈主类用户进行多轮对话的才智,视察LLM的领导保留、用户信息推理系念、可靠版块裁剪和自我一致性等4方面上的领导遵守、高下文分拨和在高下文中推理的才智。
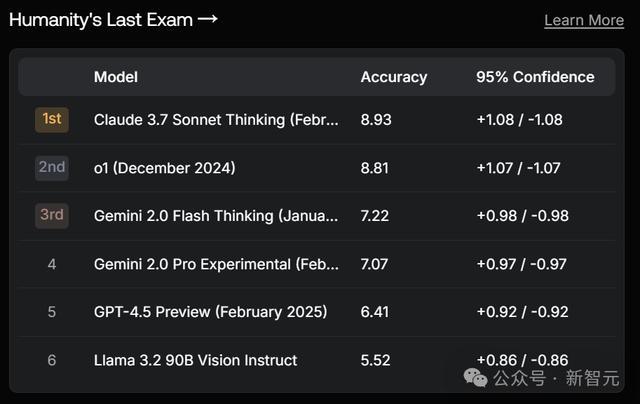
在「东谈主类临了一次历练」中,排在第5。
此次,它不仅输给了Anthropic的Claude,就连Gemini也骑在了它的头上。致使,照旧Flash版块。
顾名想义,这里测试的是LLM推理深度(举例,宇宙级数学问题)偏激学科范围的常识广度,提供对模子才智的精准测量。咫尺,还莫得模子的真正率能达到10%。
千万不要用来编程
笔据Aider的LLM编程名次榜,OpenAI旗下AI模子性价比齐不高,而GPT-4.5是性价比最差的。
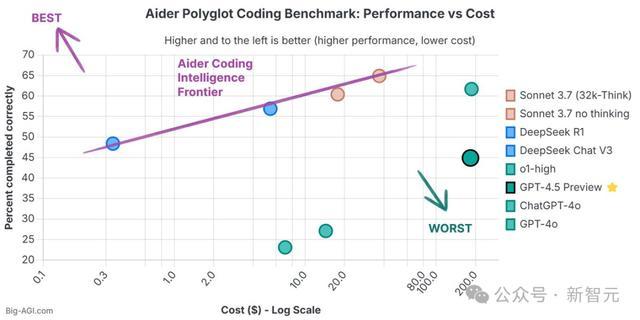
创立AI公司的Enrico则示意,除非你欢乐作念「冤大头」或「东谈主傻钱多」,不然在编程中不要使用GPT-4.5。
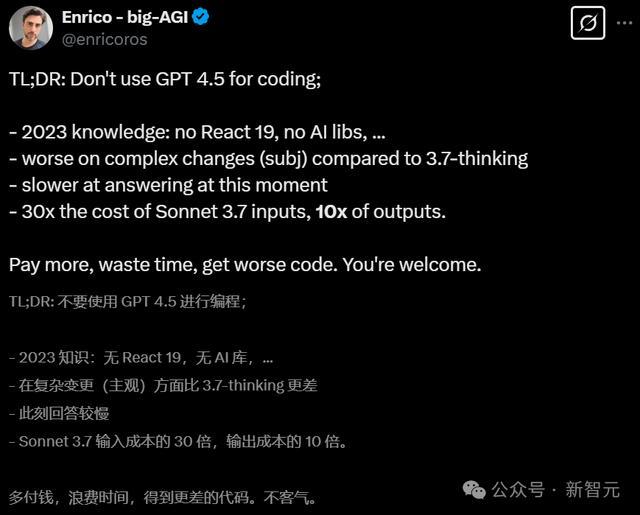
但其实,这些表象或者也在根由之中,毕竟按照OpenAI的说法,此次既不看才能也不看性能,而是强调「啥齐懂」和「情商高」。
OpenAI首席筹谋官:咱们还能Scaling!
天然外面的争论荒谬强烈,但在OpenAI首席筹谋官Mark Chen看来,GPT-4.5的发布恰是证实模子在限制上的Scaling还没达到极限。
同期,对OpenAI而言,GPT-4.5亦然对那些质疑「Scaling模子限制不错连续取得进展」的回复:
「GPT-4.5实确凿在地讲明了咱们不错连续沿用Scaling Law,况且代表着咱们一经迈入了下一个数目级的发展阶段。」

预西宾和推理,两条路并行
如今,OpenAI正沿着两个不同的维度进行Scaling。
GPT-4.5是团队在无监督学习上最新的推广实验,与此同期,团队也在鼓吹推理才智的进展。
这两种形式,是相得益彰的:「为了构建推理才智,你领先需要常识基础。模子不行盲目地从零开动学习推理。」
比较起推理模子,领有更多宇宙常识的GPT-4.5,在「智能」的体现方式上实足不同。
使用限制更大的言语模子时,天然需要更多时刻处理和想考用户提议的问题,但它依然能够提供实时的反馈。这少量与GPT-4的体验杰出相同。而当使用像o1这样的推理模子时,它需要先想考几分钟致使几分钟,才会作答。
关于不同的场景,你不错选拔一个能够立即回复、不需要万古刻想考但能给出更优质谜底的言语模子;或者选拔一个需要一段时刻想考后才能给出谜底的推理模子。
笔据OpenAI的说法,在创意写稿等范围,更大限制的传统言语模子,在发扬上会显耀优于推理模子。
此外,比较于上一代GPT-4o,用户在60%的日常使用场景中也更可爱GPT-4.5;关于坐褥力和常识责任,这一比例更是高潮到了近70%。
GPT-4.5合适预期,莫得特别贫困
Mark Chen示意,OpenAI在筹谋形式上杰出严谨,会基于悉数之前西宾的LLM创建展望,以细目预期的性能发扬。
关于GPT-4.5来说,它在传统基准测试上展现出的更正,和GPT-3.5到GPT-4的跃升不错说十分访佛。
除此除外,GPT-4.5还具备了好多新的才智。比如制作早期模子齐无法完成的——ASCII Art。
值得一提的是,Mark Chen特别指出——GPT-4.5在确立经过中并莫得特别贫困。
「咱们悉数基础模子确凿立齐是实验性的。这常常意味着在某些节点住手,分析发生了什么,然后再行启动运行。这并非GPT-4.5特有的情况开云kaiyun,而是OpenAI在确立GPT-4和o系列时齐选择的形式。」